Let's Encrypt 如何運作 CT 日誌
Let's Encrypt 在今年春天推出了憑證透明度(CT)日誌。我們很高興分享我們如何建立它,希望其他人可以從我們的經驗中學習。CT 已迅速成為網際網路安全基礎架構的重要組成部分,但不幸的是,運作良好的日誌並非易事。CT 社群越能分享已完成的工作,生態系統就會越好。
Sectigo 和 Amazon Web Services 慷慨地提供了支援,以支付我們 CT 日誌運作的絕大部分費用。「Sectigo 很榮幸能贊助 Let's Encrypt CT 日誌。我們相信此舉措將為 CT 生態系統提供急需的強化。」Sectigo 的資訊長 Ed Giaquinto 表示。
如需更多關於 CT 及其運作方式的背景資訊,我們建議閱讀「憑證透明度如何運作」。
如果您對我們在此處撰寫的內容有任何疑問,請隨時在我們的社群論壇上提問。
目標
- 規模: Let's Encrypt 每天發行超過100 萬張憑證,而且這個數字每個月都在增長。我們希望我們的日誌不僅能使用我們的憑證,還能使用其他 CA 的憑證,因此我們需要能夠處理每天 200 萬張或更多的憑證。為了支援這種不斷增加的憑證數量,CT 軟體和基礎架構需要針對規模進行架構設計。
- 穩定性和合規性: 我們的目標是 99% 的正常運作時間,且任何中斷時間不得超過 24 小時,並符合 Chromium 和 Apple CT 政策。
- 分片: CT 日誌的最佳實務是將其分成數個時間分片。如需更多關於時間分片的資訊,請查看這些部落格文章。
- 低維護: 人力成本很高,我們希望盡量減少維護基礎架構所需的時間。
系統架構
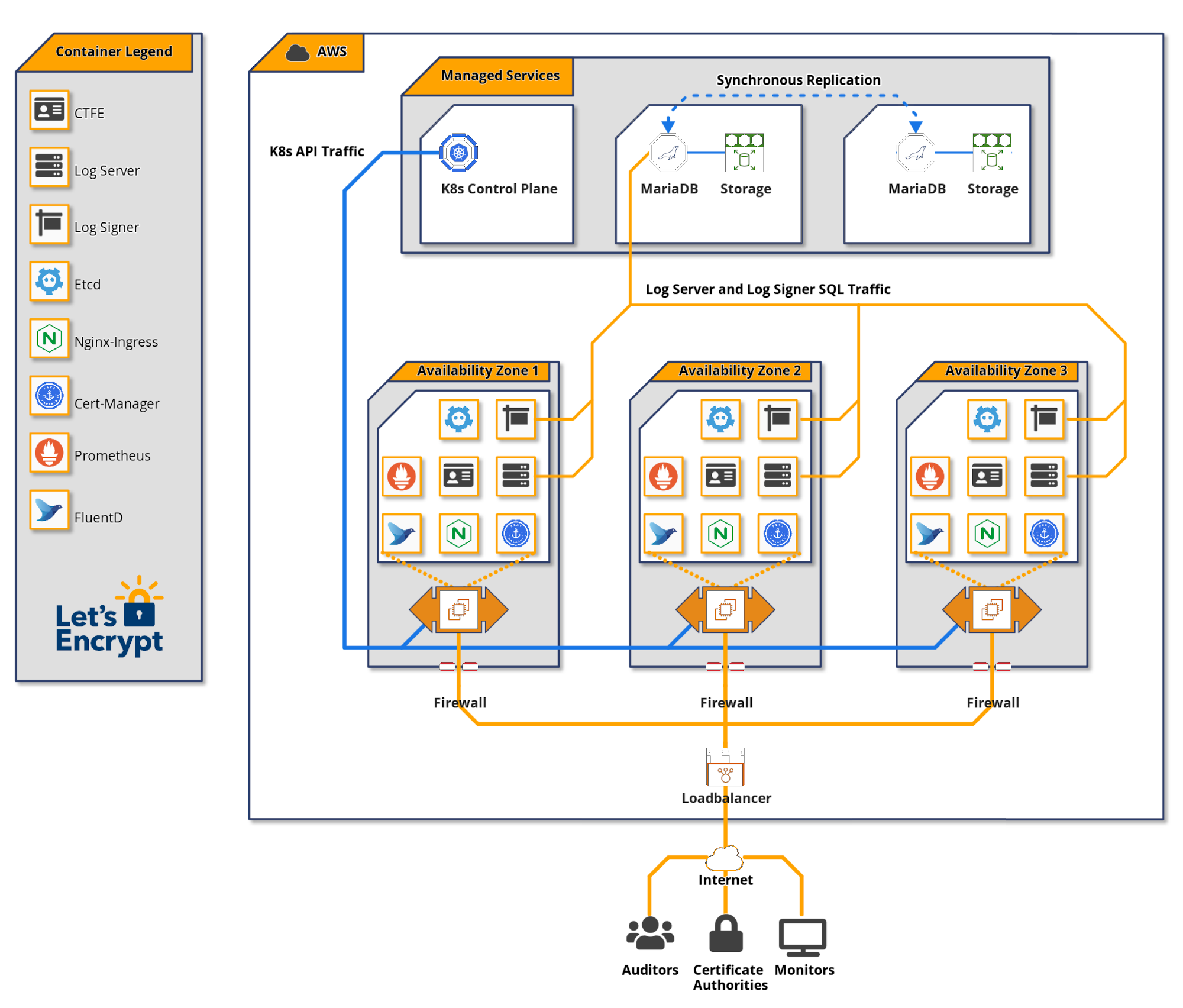
預備環境和正式環境日誌
我們運作兩個對等的日誌,一個用於預備環境,一個用於正式環境。任何我們計劃對正式環境日誌所做的變更,都會先部署到預備環境日誌。這對於確保更新和升級在部署到正式環境之前不會造成問題至關重要。您可以在我們的文件中找到這些日誌的存取詳細資訊。
我們讓預備環境日誌持續處於正式環境等級的負載下,以便任何與規模相關的問題都能先在此處顯現。我們也使用預備環境 CT 日誌提交來自我們預備環境 CA 環境的憑證,並使其可供其他 CA 的預備環境使用。
在此澄清一點,我們認為一個日誌是由數個時間分片組成。雖然每個分片在技術上都是一個單獨的日誌,但將這些分片概念化為屬於單一日誌是有意義的。
Amazon Web Services (AWS)
我們決定在 AWS 上運作我們的 CT 日誌,原因有兩個。
我們的一個考量是雲端供應商的多樣性。由於生態系統中受信任的日誌相對較少,我們不希望多個日誌因單一雲端供應商中斷而停機。在我們做出決策時,有些日誌在 Google 和 Digital Ocean 的基礎架構上運作,也有些是自我託管的。我們當時不知道 AWS 上有任何日誌(事後看來,我們可能錯過了 Digicert 已開始將 AWS 用於日誌的事實)。如果您正在考慮設置一個供 CA 使用的受信任日誌,請考慮雲端供應商的多樣性。
此外,AWS 提供了一套可靠的功能,而且我們的團隊在將其用於其他目的方面擁有豐富的經驗。我們毫不懷疑 AWS 可以勝任這項任務。
Terraform
Let's Encrypt 將 Hashicorp Terraform 用於許多雲端專案。我們能夠透過重複使用我們現有的 Terraform 程式碼來引導我們的 CT 日誌基礎架構。我們的 CT 部署中大約有 50 個元件;包括 EC2、RDS、EKS、IAM、安全群組和路由。集中管理此程式碼使我們的小團隊能夠在全球任何 Amazon 區域重現 CT 基礎架構、防止組態偏移,並輕鬆測試基礎架構變更。
資料庫
我們選擇使用 MariaDB 作為 CT 日誌資料庫,因為我們在將其用於運作我們的憑證授權機構方面擁有豐富的經驗。MariaDB 在我們成為最大的公開信任憑證授權機構的過程中擴展良好。
我們選擇讓我們的 MariaDB 執行個體由 Amazon RDS 管理,因為 RDS 提供對備用叢集成員的同步寫入。這允許自動資料庫容錯移轉並確保資料庫一致性。對資料庫複本的同步寫入對於 CT 日誌至關重要。在資料庫容錯移轉期間,遺失一次寫入可能意味著憑證未按承諾包含,並可能導致日誌被取消資格。讓 RDS 為我們管理此功能可降低複雜性並節省人力時間。我們仍然負責管理資料庫效能、調整和監控。
仔細計算 CT 日誌資料庫所需的儲存量非常重要。儲存空間太少可能會導致需要進行耗時且可能存在風險的儲存遷移。儲存空間太多可能會導致不必要的高成本。
簡單的儲存估計是每 1 億個條目 1TB。我們預計每年每個時間分片需要儲存 10 億張憑證和預先憑證,為此我們需要 10TB。我們考慮過為每個年度時間分片使用單獨的資料庫儲存空間,每個分片分配大約 10TB,但這在成本上是無法接受的。我們決定為每個日誌建立一個 12TB 的儲存區塊(10TB 加上一些緩衝空間),該區塊由 RDS 複製以實現冗餘。我們計劃每年凍結前一年的分片,並將其移至成本較低的服務基礎架構,回收其儲存空間以供我們的即時分片使用。
我們為每個 CT 日誌的 RDS 使用 2 個 db.r5.4xlarge 執行個體。這些執行個體中的每一個都包含 8 個 CPU 核心和 128GB 的 RAM。
Kubernetes
在嘗試了幾種不同的策略來管理應用程式執行個體之後,我們決定使用 Kubernetes。Kubernetes 的學習曲線很陡峭,這個決定並非輕率做出。這是我們第一個使用 Kubernetes 的專案,我們之所以選擇它,部分原因是为了獲得經驗,並可能在未來將該知識應用於我們基礎架構的其他部分。
Kubernetes 為操作員提供了抽象,例如部署、擴展和服務探索,這些我們不必自己建立。我們利用 Trillian 儲存庫中的範例 Kubernetes 部署清單來協助我們的部署。
Kubernetes 叢集由兩個主要元件組成:控制平面(處理 Kubernetes API)和工作節點(執行容器化應用程式)。我們選擇讓 Amazon EKS 管理我們的 Kubernetes 控制平面。
我們為每個 CT 日誌的工作節點集區使用 4 個 c5.2xlarge EC2 執行個體。這些執行個體中的每一個都包含 8 個 CPU 核心和 16GB 的 RAM。
應用程式軟體
我們在 Kubernetes 叢集中運作三個主要的 CT 元件。
憑證透明度前端,或 CTFE,提供 RFC 6962 端點,並將其轉換為 Trillian 後端的 gRPC API 請求。
Trillian 將自己描述為「透明、高度可擴展且可加密驗證的資料儲存」。本質上,Trillian 透過 Merkle 樹實作通用可驗證資料儲存,該樹可以作為透過 CTFE 的 CT 日誌後端。Trillian 由兩個元件組成:日誌簽署器和日誌伺服器。日誌簽署器的功能是定期處理傳入的葉子資料(在 CT 中為憑證),並將它們納入 Merkle 樹中。日誌伺服器從 Merkle 樹中擷取物件,以滿足 CT API 監控請求。
{kind=link}
負載平衡
流量透過映射到 Kubernetes Nginx 輸入服務的 Amazon ELB 進入 CT 日誌。輸入服務在多個 Nginx Pod 之間平衡流量。Nginx Pod 將流量代理到 CTFE 服務,後者將流量平衡到 CTFE Pod。
我們在此 Nginx 層使用基於 IP 和使用者代理的速率限制。
記錄和監控
Trillian 和 CTFE 會公開 Prometheus 指標,我們將其轉換為監控儀表板和警示。必須為 CT 日誌端點設定高於 CT 政策所規定的 99% 正常運作時間的服務等級目標,以確保您的日誌受到信任。在 DaemonSet 中執行的 FluentD Pod 會將日誌傳送到集中式儲存空間以進行進一步分析。
我們開發了一個名為 ct-woodpecker 的免費開源工具,用於監控日誌穩定性和正確性的各個方面。此工具是我們如何確保達到服務等級目標的重要組成部分。每個 ct-woodpecker 執行個體都在包含 CT 日誌的 Amazon VPC 外部執行。
未來效率改進
以下是一些我們未來可能可以提高系統效率的方法
- Trillian 會儲存每個憑證鏈的副本,包括許多相同中繼憑證的重複副本。能夠在 Trillian 中對這些進行重複資料刪除將大大降低儲存成本。我們計劃研究這是否可能且合理。
- 看看我們是否可以成功使用比 IO1 區塊儲存和佈建 IOP 更便宜的儲存形式。
- 看看我們是否可以縮小 Kubernetes 工作節點 EC2 執行個體的大小或使用更少的 EC2 執行個體。
支援 Let's Encrypt
為了提供我們的服務,我們仰賴使用者社群和支持者的貢獻。如果您的公司或組織有興趣了解更多關於贊助的資訊,請發送電子郵件至 sponsor@letsencrypt.org。若您有能力,我們也懇請您進行個人捐款。